

Python Web Scraping - Batch Download Web Articles
Published
•3 min read
A
Code Cruncher, Data Science Enthusiast, Anime Nerd, Sir Read-A-Lot!
We will be scraping Sanfoundry 1000 MCQs to download subject-wise MCQs. Visit Sanfoundry homepage and copy URL of 1000 MCQ based page of your subject choice.
NOTE:Arbitary Links for Reference (Only works for 1000 MCQs homepage)
https://www.sanfoundry.com/1000-python-questions-answers/
https://www.sanfoundry.com/1000-digital-image-processing-questions-answers/
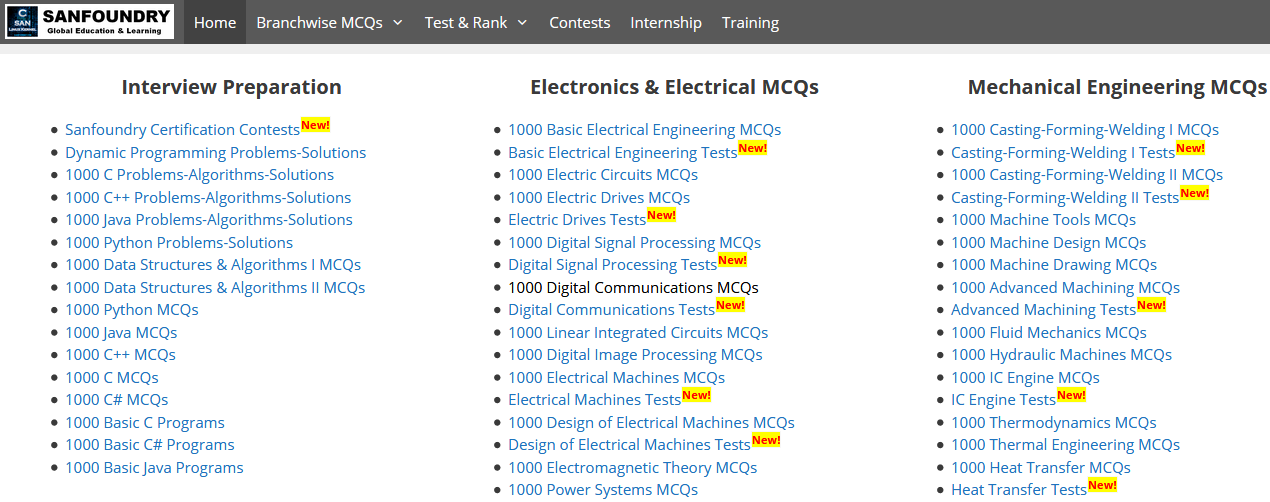
 Once you grab the desired topic URL, we can start writing our Python Script.
Once you grab the desired topic URL, we can start writing our Python Script.
Step 1. Importing Dependencies.
import sys
import re
import urllib.request
from bs4 import BeautifulSoup
from urllib.request import Request, urlopen
Step 2. Initiate Web-Scraping and configure browser settings automatically.
req = Request('https://www.sanfoundry.com/1000-fluid-mechanics-questions-answers/',
headers={'User-Agent': 'Mozilla/5.0'})
webpage = urllib.request.urlopen(req).read()
html_page = urlopen(req)
soup = BeautifulSoup(html_page, "lxml")
Step 3. Grab all the topic-wise links and store them in a text file.
We are using the append mode so you can add multiple 1000 MCQ based URLs and all the scraped topics will be appended to the end of the text file.
links = []
for link in soup.findAll('a'):
x = re.search("-answers-", str(link))
if x:
links.append(link.get('href'))
for link in links:
with open("output.txt", "a") as f:
print(link, file=f)
print('\n', file=f)
NOTE: The Text file will be saved @ TermainlPath>output.txt so change you can cd from terminal and execute script there.
Step 4. Copy All Generated Links from Text File to Batch Download Webpage
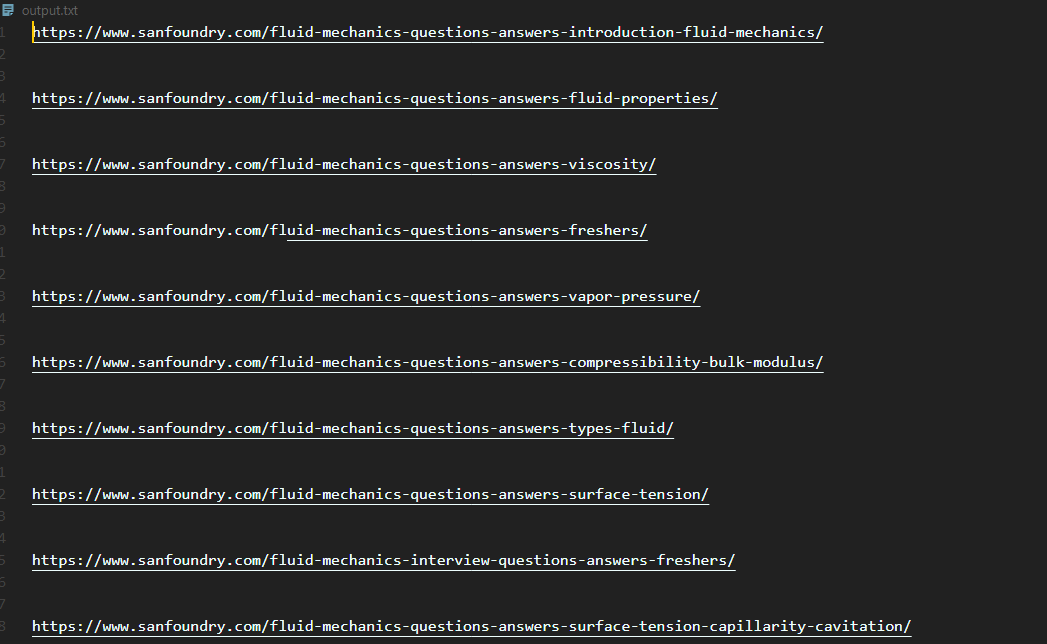
Step 5. Open all the downloaded HTML files and read offline, at our pleasure.
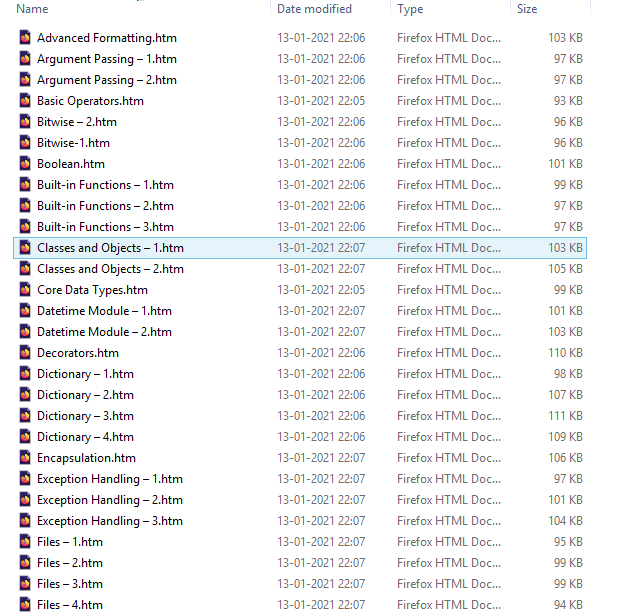
Grab the full code here.
import sys
import re
import urllib.request
from bs4 import BeautifulSoup
from urllib.request import Request, urlopen
req = Request('https://www.sanfoundry.com/1000-fluid-mechanics-questions-answers/',
headers={'User-Agent': 'Mozilla/5.0'})
webpage = urllib.request.urlopen(req).read()
html_page = urlopen(req)
soup = BeautifulSoup(html_page, "lxml")
links = []
for link in soup.findAll('a'):
x = re.search("-answers-", str(link))
if x:
links.append(link.get('href'))
for link in links:
with open("output.txt", "a") as f:
print(link, file=f)
print('\n', file=f)
If you liked this article, please drop and like and follow me on Twitter to support this blog. Have a great day.



